Back to Webinars
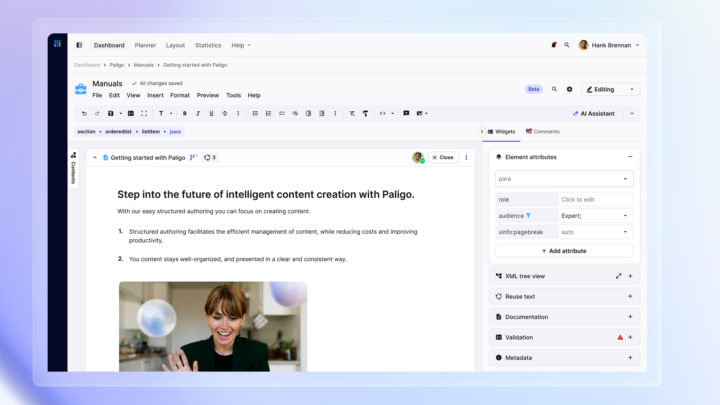
Hi, everyone. My name is Andy, and welcome to today's webinar, preparing and delivering content for successful AI deployment with Paligo and Zoomin. Please submit your questions in the q and a box, and we'll do our best to address them all at the end. And now I'll hand you over to our panelists, Joe Gelb and Josh Anderson. Very good. Thanks very much, Andy. Hi, Josh. Good morning. Hi, Joe. Thanks, Andy. Very good. Okay, Josh. Happy to be, collaborating with you on this on the webinar. We're gonna go ahead and blast forward. Awesome. Yeah. Glad to be here with you. So no. We're we're gonna be talking a lot about AI, and we're talking about technical content. But, I think one thing we wanna just kinda start out with with you know, there's a lot of buzz around AI, but I think we're all understanding more and more. That message is us, but I think a lot of people in the world are understanding that that the value that you can get out of AI is really driven by the data that you put into it. You know, we're seeing a lot of adoption, more and more adoption of AI. And, again, we're we're understanding more and more that the data and the content that's being put into those AI applications is becoming more and more important. Not really the kind of creates one of these flywheels where the more we understand the importance of data and the data being updated and learning how to update that content in the in the proper way and the most effective way, that will drive more and more value and more and more and more and more adoption. Yeah. So I think a lot of us have this awareness that AI is just transforming everything about the way we work, including the ways that we work with content. So a lot of us know that there's these huge quality and speed gains that can be made with AI, but we also know that probably there's more we could be doing with it. Like, how do we utilize the power of AI for improving analytics, customer self-service, knowledge based searches. So, we wanna explore today a little bit how we do that right. Yeah. And so the first thing I think we should be a little clear about is that when we're talking about, how AI can improve our writing and our content processes, there's sort of a difference between writing with AI versus writing for AI. I think of writing with AI as another way of saying prompt engineering. So this is, kind of a popular phrase nowadays. You write a prompt in a specific way in order to manipulate the outcome that will be generated by the AI. But that's not really what we're focusing on today. We wanna write for AI, which is writing structured content that's optimized for ingestion by large language models to inform AI powered applications, which is a a bit of a less explored topic, I think, but it's what Joe and I want to discuss today. Mhmm. Got it. The question is, like, why is this so important? And, especially in our industry, and a lot of you are probably technical communicators or in the technical content creation, area. And this is becoming more and more important for people like us because many companies are understanding that, and our customers are understanding that this content and AI related content is becoming more and more important. Like, according to this, this is secure. Thirty seven percent of companies are actually adopting conversational AI. So you can say, well, that's a small number. It's not a majority, but there's still a pretty big number considering the, you know, how new this technology is. But most companies, about fifty nine percent, predict that the Gen AI is gonna be a major disruption in techcomm, technical communications, and and self-service and really everything that's you know, the whole the whole ecosystem, the power of content is being is, is being delivered and how it's being impacted and what and the and the impact that it has in our products. So I wanna talk a little bit about the methods and technology used for AI applications, kinda set a baseline. You probably heard a lot of different words or different different terminology. Wanna kinda set a baseline, and we'll talk a little bit more about that later on. So maybe maybe you heard maybe of this idea of retrieval retrieval augmented generation when it comes to AI. So with AI, the idea of of RAG means that we're taking a traditional search and combining that with general gen AI. Meaning, now let's say you have, your content is being fed into a search engine. It could be, you know, a a keyword search engine like we're used to or it could be maybe a a more modern semantic search engine. But the idea basically is that we're retrieving content from a search. And then based on search results, we're going and generating generating an answer, which hopefully will be more accurate and and more concept context aware than just doing a regular search. So that's the idea of RAG. We we treat for augmented generation as it comes as it relates to GenAI. Embeddings is the idea of using a machine language model for mapping words or documents into vectors. So you've heard of this idea of vectors. The idea of taking content or, you know, it's word or whole documents and basically using a model to to turn that into a set into a vector. That's really what the idea of embeddings is called. And that those embeddings are then stored, in a vector database. So we have this vectorization meeting representing that meaning, the semantics or the meaning of these words or these documents as embeddings. That's called vectorization. Vectorization encoding these as numerical vectors and then storing those in the vector database. Now semantic search as opposed to keyword search allows us to basically take the query that somebody's asking or the question that someone's asking. We actually use the same embeddings mechanism to understand the semantics or meaning of the question, and then we do a search of that semantic question across the semantics of the content that which is stored in that vector database. Okay? So instead of searching on keywords or words or free text, we're actually searching on meaning. That's what's kind of cool about the whole idea of semantic search is actually doing a search on the meaning or the vector the as representatives vectors and searching and hopefully finding, you know, hopefully finding a more precise or more, more precise answer based on the meaning of my question. Now the relevance actually helps to improve the understanding of the words of the documents based on this, again, this content generation. That's really gonna baked into the whatever AI system you're putting together. Last two tech tech terminologies I wanna bring bring forward is the idea of grounding. Now grounding is the ability basically to connect your model or your application onto verifiable verifiable sources of information. What that means for us is that if we're creating our own AI applications in our company for self-service or for self-service chatbots or for helping our service agents to get better answers or our customers, the idea is being able to ground our AI applications on our own content, content that we've written or that we verified, and not the public Internet. So the idea is that we wanna ground the content, the ground the apps on our content and not anyone else's content. The last thing I wanna bring out, which is becoming more and more interesting is this idea of multimodal and the idea of of processing information from different types of content or modalities such as images or videos as opposed to text. So actually being able to understand the meaning of an image and use that as part of our model. And, we've been able to see a lot, you know, very interesting results. If you're able to actually understand what an image is saying and use that as part of your model, that becomes very, very interesting. Mhmm. So I wanna talk a little bit about what's happening with a large language model and how it kind of reads the content. Because while the answers that AI will give is often very convincing, I think it's important to not lose sight of the fact that LLMs are not designed to generate true facts, but they're more designed to generate or to guess the most probable next tokens or words. If I ask an LLM to complete the phrase roses are red, violets are what, it's probably going to say blue because it's encountered that pattern of words throughout the content set that it was trained on many more times than it ever encountered. Violets are orange or violets are flowers or whatever it is. Like, it doesn't know violets are blue. It's just seen that so many times. And so some LLMs will offer parameters like temperature that will let you kind of customize the predictability or the randomness of the responses you receive. But the LLMs idea of the most proper response, again, doesn't come necessarily from what's true, but rather from what it has encountered most frequently in its training. And so the AI reads your content not really by identifying facts, but by turning the words into numbers embeddings, as Joe mentioned, which encode meaning. And let's talk a little bit more about how it does that on the next slide. So words get embedded into certain locations in a multidimensional semantic space. And as the LLM is trained on more and more content, the words that tend to appear together, gradually cluster together in this semantic space. And so some of the things you can do, surprising and interesting things you can do, because of that are like semantic math. So you could take, say, the vector for, the word Paris, subtract France, add Italy, and then you arrive at a location that's basically the vector for Rome. And so in the example on the slide here, if you write the in your prompt, the words dog, leash, and outside, the fact that the LLM's answer will likely relate to a dog walk isn't really because the AI grasps dogs and leashes and why they'd be associated with each other, but because those words have appeared together many times throughout the set of texts that the large model was trained on, and therefore, by adding those vectors together, the LLM gets pointed towards dog walk. So how does this relate to one's own content? So some people will assume will assume that, in order to get an LLM to be able to answer questions about your own content, you would have to train an LLM yourself with many, many more examples of facts that you wanted to internalize. But that's a very costly way of doing things. It's not a efficient way because you need to redo it when there's new facts that you wanted to learn. So, as Joe mentioned, you're probably better off with a retrieval augmented generation or rag type architecture. So if I ask an LLM to help me reset my password, for a particular product, it won't inherently know enough about my product to give me a useful answer. But instead, when we use this reg architecture, it takes the word embedding of my prompt, which is please reset my password, then it queries the vector database of my content. It finds the semantically similar topic instructions to perform a password reset and then adds it to my prompt as context. So then the prompt, which at this point consists both of the question I typed as well as the inserted topic for context goes to the LLM. And so that's how it's able to give me an answer that's relevant to my own content. And that kind of leads to the question of how we can write our content so it's best surfaced at the proper time, in order to provide an accurate and pertinent answer. And so on this slide here, we've got some general principles. Ideally, content should be, self contained written about one thing at a time because the risk if you don't do this is that it's going to be chunked by an algorithm that robs your content of its full, semantic richness and meaning. Writing these small self contained topics, also has the effect down the line of saving you money by not wasting tokens on including unnecessary, text in the context of your prompts to give to the LLM. Also, the more metadata you can provide, the better. We wanna give the AI hints about the nature of the content, its intended audience, its intended reader response. Also, self explanatory semantic element and attribute names are a feature of, structured markup language like XML. So if you have your content in a CCMS such as Bligo, it'll be kept in XML, meaning that it's ready to be ingested by AI applications such as those offered by Zoom in. So on this slide here, we're talking a little bit about, this idea of chunking content, which is important for LLMs in order for them to work efficiently. So, I wanted to include a quote from this recently released book. See if it shows up on camera here. It's from, O'Reilly. I'll be reviewing that in the, future issue of technical communication. But it's called prompt engineering for generative AI. And what they point out is that, chunking along a topic or a section or some kind of, you know, logical unit, is a strategy that's well suited for certain tasks like text classification, content recommendations, and clustering. I have another quote on the slide after this one. This is from a paper by Stephen DeRose presented earlier this month at, Bellisage, the markup conference. And so he also notes that when you chunk along logical units such as sections, that's advantageous over other chunking strategies like, you know, some arbitrary character length. And so the reason is that the chunks get pulled into the prompt by the LLM, and they'll contain the necessary context to be able to effectively answer the user's question. There's one more citation on the next slide here. So this is a quote from Mark Gross from the same conference, and he singles out that a consistent and accurate XML structure is something that ensures content will be AI ready. And so, again, when you have content stored in a CCMS such as Pligo, it is in such an XML structure, and therefore, it's ready to inform AI applications like, ZoomIn. And so Joe will take the next slide to put the pieces together. Great. Great. Thanks very much. Yeah. It's a great, run through of of how these Lander can be related to what to our industry and what we're talking about. So we put all the pieces together of these technologies. So we have, you know, we have content coming from, you know, from different sources, let's say, from technical content. We have the embeddings that are, you know, that are the semantics of that, which are stored in the vector database. We have the LM that Josh ran us through, which is that language model that's really kind of using the vector database as the what you know, the application basically takes a vector database from the routing mechanism and then combines that with the language model and is able to serve up an AI AI application. In our case, it's probably a self-service portal or some kind of a virtual agent or or or, some kind of a self-service bot. Now some things we need to be concerned with in our in our space is number one, unifying this knowledge. Meaning, we might be writing technical documentation content such as in ProLogo, but we all might have other content as well that we need to be concerned about that can be used in order to help ground our applications. For example, knowledge based articles or learning content. We also need to be concerned with enforcing access control. Meaning, just like before, we we were concerned about having our content. Some content is only available to customers. Some content is available only internally. Some content maybe would be public facing. But in any case, we wanna make sure that the AI applications are not serving up answers or generate answers generated by AI based on content that are this particular user is not allowed to see. We're starting to be concerned with that, as well as making sure that we're identifying and masking out any kind of sensitive data. Now a lot of technical documentation content typically does not have PII in their personal information. But if we're if we're bringing other content into the mix to help serve serve, like, a knowledge articles or cases or things like that, so we definitely wanna make sure to scrub this information, make sure the personal information is not be, available to into to be training any of our models. So to recap, what we need to be AI ready really is unifying our knowledge, meaning, unifying that that knowledge which is always updated in a single source of truth. And, again, in our space, we're talking about documentation, talking about structured documentation, talking about other knowledge that are being created by our engineers that might be useful, knowledge articles, learning content, things like this. That needs to be unified together into for AI applications. We also need to have some governance around the content, security and private privacy being enforced. And then we need to have those LMs and AI capabilities. Again, as Josh mentioned before, how we're training those LMs, how we're chunking content, etcetera, also has an impact on the on the optimization or the effectiveness of these of the applications. Yeah. So as Joe noted, unified knowledge is what we need in order to be AI ready, and it it's critical for a number of reasons. So first, there's the enhanced understanding that can come only when you have a complete comprehensive set of content to draw from. So then you'd have improved accuracy and reduced ambiguity, out of date or contradictory information that's still floating around in your documentation might confuse an AI because it wouldn't know which is the best response to return. And so, CCMSs such as Poligo are great at enabling single sourcing, the best practice for technical writers, which means that the same unit of information is reused in multiple places. Importantly, you can update it in one place, and then you can know that it has been updated in all the places where it lives. And then increased productivity will come as you eliminate the need to switch between different, sources or search engines. All of this leads to an improved user experience. But, of course, this is easier said than done as Joe will point out on the next slide. Exactly. Yeah. So we're talking about this idea of unified knowledge, and the question is, like, you know, why is that? You know? So when we talk about self-service, I I know probably a lot of people in the audience, either are working for for knowledge management organizations or work or have knowledge management or support organizations in their in their in their company. And, the problem is that a lot of the content that they're using in their self-service portals or inside their CRM systems, they're not available. Meaning, they have knowledge articles, support cases, any kind of CRM, any kind of community discussions, but eighty percent of the content is really not there. All your content, the product documentation, user manuals, AAPI documentation, all this kind of content, training guides, release notes, IFUs, instructions for use, all that content was being written in the legal, but also maybe in Confluence and other content that maybe around that maybe your engineers are writing or that's just kind of being fed in by other people in the organization besides technical documentation experts. All the content is not available in in these, self-service applications, not being used to ground these applications. These are the AI applications. That's really the problem that we're facing, and that's really where unified knowledge comes to bear. And that's really where where you Zoom in comes in as a, from a from a from a architectural model point of view, kind of, is really perfectly suitable for for CCMSs, like, for structured content like the legal in order to kinda bring that content in to a to be able to ground these these knowledge, knowledge portals and these, these AI applications much more effectively. Now if we talk about unifying knowledge in a little more granular way, We understand that there's, again, technical documentation being created in CCMSs. Like, as Polycom, we have API documentation, like like in Swagger, maybe markdown, learning content, different LMSs, support tickets, knowledge articles might be created in the CRM system like Salesforce or maybe like ServiceNow or Zendesk, community discussions. All that content needs to be brought into that unified platform. That's really what allows that unified or that unified updated source of truth allows that gives you the gives you the ability to create that content governance, that security that security architecture, that security model and policy, but also gives you that API first model. So if someone comes to your from your organization and says, listen. I'm developing our own chat CPT bot, and I want access to your content. Because here, here's our API. We've we've got our content being ingested into this API. We already have our taxonomy set up there. We as long as you're able to go ahead, authenticate into the API that we as a technical content organization is providing you, there will content delivery platform, then you can go ahead and you can create your own applications based on the content that we know is it's always updated and has that that unified source of truth. It also allows you to have a a documentation site or a portal, allows you to take this content, not just your documentation content, but also maybe knowledge articles and learning content, make that available inside your products, allows you to provide your content inside the service portals or inside actually the CRM. So as an as a knowledge organization, the CTP is this content delivery path delivery platforms allows you, the leverage really to be able to take your content, combine it with other content in the organization, and really allows the act that access to to, to be use upstream in different applications. So talk about content content governance. I wanna do a little bit of a, deeper dive on this or kinda spotlight this a little bit. So a lot of companies are concerned, wait a minute. I don't wanna use AI because, you know, because there's different legal issues with it. I'm I'm concerned about, you know, where our AI application are getting their their answers from. So number one, we wanna make sure that you are only using your curated content for grounding. We mentioned that a little bit earlier when we talked about grounding. So we wanna make sure that your applications are grounded on your on your content, be it that unified knowledge application or or, framework and not grounding your content in any kind of public repositories. Even if you're using APIs like open API, you there are ways that you can go ahead and make sure that you're only grounding on your content and not public content. Second thing is you wanna make sure that your AI applications are not afraid to say, I don't know. Meaning, they should have a healthy dose of humility and not, give into fuzziness. As we all know, these AI AI applications, and Josh kind of alluded to this before, they're gonna make up content based on what they've seen. But if they don't if they if they don't see an answer, you want them to be able to say, I don't know the answer and basically dial down what's called the fuzziness factor so that they don't go ahead and make up answers to questions on your on your self-service site. You wanna make sure that content is sanitized like we mentioned earlier. You wanna make sure that you have hooks for legal disclaimers. A lot of us have legal counsel in our companies, kind of using that tongue in cheek, and they often have a lot to say about how AI is being rolled out. Wanna make sure that they have the proper hooks to to put their legal disclaimers inside of your applications. Again, you wanna make sure that you have the proper control over permissions and role groups so that when people are authenticating into your applications or if they're coming in from the public, knowing that they're coming from the public and you and you don't necessarily know who they are. You wanna only present AI content or AI answers based on what they're allowed to see. And the last thing also, which is very important a lot of companies are are concerned about, is not allowing other models to train on your content. So if you're using public APIs, you wanna opt out of any possibility for third party vendors to be using your content to train their models. Yeah. So let's, review a little bit about how structured authoring and writing and that kind of style helps you optimize your content for AI ingestion. And so when you have a structured authoring platform such as Pligo, it makes use of in standard like XML. Pligo in particular has mechanisms to prevent you from saving your content in an invalid state. So that's important. There's also ways to add metadata to content through the names of the elements that you use, the attributes you add, including those used for filtering or profiling for different audiences and so on. Taxonomy tags help with this as well. You can also access your content through an API, which should make it compatible with other applications. But I think a big benefit is that by following the best practices of writing topics in a short self contained micro content type of format, you allow these, retrieval augmented generation style AI systems to identify and retrieve the best, most pertinent, and accurate information to serve up in the responses to user queries. And if the content has been chunked along topic boundaries, it'll keep costs low by optimizing token usage in your prompts to the large language model because in that case, it'll include only the necessary context, no more and no less. Right. Very good. Okay. So we're gonna kinda pause the slides a little bit and show a little bit of a, kinda show and tell. So we're gonna show a little bit of, how Pilego and Zoom and can work together to show the ease of authoring and publishing and then show how that content can actually be, surfaced up in the AI in AI generated right application or to generate answers. Mhmm. So the first thing I'm gonna show you on the screen here is Polycom. So, Josh, feel free to walk through this, what we're seeing on the screen here. Sure. Yeah. So what we're looking at here is the authoring mode in Poligo. So this is what, regular authors would look at as they're writing their content. It is they're writing in a structured authoring format. In the background, it's all XML, but, there's not really, like, code and tags and things that might overwhelm, authors who don't wanna see all that. So you get the benefits of structure without necessarily the hassle of having to navigate through a really tag heavy type of interface, you might say. So in this particular topic, it's broken into a number of different sections. The whole thing's about electric vehicles, but then there are certain sections about more, specific pieces of information. And lists are broken up into list elements and everything. So the point being, this follows some best practices for structuring content. Right. What's cool about this is that if when I go to the publication, I can go ahead and very easily publish this. So when I'm publishing this to a to a CDP, for example, you know, with Josh David, when he's prepared me this for this, for this webinar, Basically, all Josh had to do is go and click on what publish and click publish to Zoom and then it came up to the to the to the demonstration I'm gonna be showing you shortly. Mhmm. It's very easy. So if I go here to the, what was to this aspect, to this part of the to the demo, what you're seeing here is a is an example of a content delivery portal, which has, some content that we published in here. And, so we see here some navigation abilities to go and navigate through content and be able to see, navigate through different types of content. For example, if I have different types of products and different version of products, being able to get the aggregated view or unified view of content whether it's coming from technical documentation or, you know, case studies or knowledge articles or API documentation, FAQs coming from a CRM or from a or from a, from a knowledge base, etcetera, etcetera. What I wanna do here is is first of all, let's just go and see the content that that Josh published in here. So if we go and click on electric vehicles, so we see that coming up in the search. I click on that. So we see this content in here that that Josh had published into this portal, and we can see the the, the entire hierarchy that was published from that publication here. Mhmm. Now what's what's interesting here and kind of go going back and and tying this into the conversation we're seeing before, is that I can do a search like I just did before, or I can tie in a search with a with a, with an with a GPT based question. So I instead of just searching for electrical vehicles, I can ask a question. For example, you know, what kind of battery should I get for an electric car? Now before Josh had published his content, the answer would have been, I don't know, because there was no content here about electrical vehicles. Mhmm. But once Josh is able to publish this content, then we're able to see not only search results, but we see Ashley on the right side here, a GPT related search going and pulling out the content that Josh had had published and actually giving me an answer about about what kind of battery I should get with an electrical car. So it tells me if an electrical car should get a lithium ion battery and why they're referred. So that's pretty cool. So I can go and ask a follow-up question. Let's say, like, okay. Well, how many kilowatts does it have? And now instead of just running another search, what we're able to do is combine the GPT functionality of saying, understanding the context of where I am in the search and say, oh, well, this person just as a user, I just searched. I'm looking for content about batteries. So the context now is about batteries, and now I'm gonna continue on that that thing. And I can say, oh, well, what if it gets too cold? Is that gonna be a problem? And, it'll give him an answer about that. And, again, all this is because Josh had had had added answers about this inside of the content. If Josh didn't put an answer, would it tell me, I'm sorry. I don't know. Or based on this context, I can't give you an answer. I can say, wow. This is great. Is it okay? It's too fast charge. Okay. And so what we're seeing here again is this idea that that it's, go ahead and pulling out very specific answers based on on the content. Now what you're seeing here on the left here is also metadata. So if I were to go ahead and click on metadata here or do any filtering, then I would be able to distinguish between different versions of content or different versions of my my products as well. Again, the metadata has a has a big, effect on the con of the answers. I can also go ahead and enter my preferences. So if I wanna go into, well, I'm interested in certain products or cert I have a certain role made. I'm a a beginner as opposed to a an expert. So being able to set up preferences based on the type of content that are being, being served up, I can go ahead and say, well, you know, I'm mostly interested in this version. I'm mostly interested in manufacturing, and I'm really I'm, I'm really an engineer. So now by presenting my preferences, I can actually change the ranking that we talked about earlier and the relevance of what the what answers that the GPT is using. So we talked about that RAV method. On going and retrieving content that's most relevant. So what's the content most relevant to me? I'm actually able to go and control that either from the back end based on permissioning, but also based on user permissions and then actually affect the ranking of the content that's being used to serve up to the GPT and then be able to generate the answer that's most relevant for me. So I think that's pretty cool. I think we're able to kinda tie on how we're able to see the structured content that Joshua was able to show inside of Caligo, how the content was structured in the hierarchy, but also how Josh had put a lot of details and from information in there, and how the GPT was able to take that and kind of construct an answer based on all that structured information that Joshua was able to put into that content. Josh, would anything else you'd like to add to this before we move on? I I just think it's, it's super interesting how quickly we can write something from scratch in Polygo. And because it's, saved in a structured format, it's just ready to go. I one click and I've published a Zoom in, and I'm already, chatting with it, with AI. So I think that's that's awesome how quickly that can happen. Right. That's pretty cool. Now let me go back to the slide. We have a couple more things to point out. So we talked about the AI and kind of background about AI. We talked about how to publish into AI and how different, concerns or considerations. We showed you a little demonstration about how so you can get done. Now the back end also, you know, from a from your point of view as technical communicators, technical strategist or content strategist, the question is how can we use the GPT and these interfaces to actually drive insights to help to fill gaps. Okay? So, on a quick end and then Josh has something to say about this as well. But very often when when as a CTP, as a content delivery platform that's providing this functionality, we're able to to not only know what content is being brought in, we're also unable to know what people are clicking on. We're also able to find out what people are asking in the GPT. So what are people searching for? Did they get an answer? Did they get a response? Did they get was a response? What was the sentiment around the response? Did was no answer provided? If not, like, what was the question? Or maybe we did provide an answer, but the customer didn't didn't click on that answer or did not did not engage with that answer. So how do we use the g the analytics to actually improve our content? I'd say that one as we've been working with a lot of companies to roll out this functionality, this GPT functionality, a lot of light bulbs been going out. We or we thought we had answers to to use the common questions, but now is after we roll this out to our customers, we're actually seeing that they're asking all kinds of questions, which we didn't even know that they had. And now we're able to go ahead and and create and create, create content in order to or or update content in order to make sure the answers are there. It's very interesting because different than than a keyword search. Keyword searches gives you some insight to what people are are thinking about, but the actual questions or the formulations of those questions actually gives us much more deep deep depth of insight about what content we have and what the gaps of the content might be. Josh, feel free to add on. Exactly. Yeah. It's one thing to know that users have been searching keywords like electric vehicles. But if there's a full, human readable sentence, you know, what kind of battery should I have for my electric vehicle? That gives you, as a content strategist, a much better idea of what kind of content is perhaps missing or, different synonyms you could be using throughout your content so that it's more easily, findable by your users. So this is all super valuable for, those of us who plan content. Right. Right. And also, if you see over time, like, how people are actually engaging with the GPT. You know, I think that as people get more and more, as we get more content available, then the GPT becomes more more useful. I'll give you kind of a case study. We have a customer who was who had rolled out GPT for the technical documentation. That was great. People were using it, but there's people are starting to ask all kinds of questions that were not answers were not coming up. And they realized, well, these answers are really being answered in knowledge based articles. So they were able to go ahead and engage with their knowledge management team and their support team and say, well, why why don't we why don't we use Zoom in to go ahead and index or bring in those knowledge articles, and then we can actually have more unified base of content in order to be the GPT. And then we start seeing these GPT searches going up and the actual click through rates go ahead and going up over time. It's important here. I'm just gonna point something out, in a high level, and then Josh will add to this as well, that it's important when you're rolling out the GPT in order to be very, I think, organized and methodical about, you know, what the kind of content you're putting out there, content you're you're allowing to be that's gated, what kind of questions people are asking. And on a week by week basis, going and looking at the doc and looking at the analytics and seeing what your results are, and then over time, kind of being rigorous about what you're checking, what kind of questions, what the answers are, what kind of answers are being given, are the answers very precise, are they too big, and what the sentiment is around those those answers. That's right. Yeah. So I think this slide illustrates the idea that, you always wanna continually improve your content even when you've hooked it up to AI. It's not necessarily a a one and done kind of thing. So over time, you wanna take notes of your performance over relevant metrics. Are the answers, relevant? Are they getting, good responses? Are are the users clicking the happy face after they read it rather than the frown face? You know, that sort of thing. So by checking in with how your users are interacting with things, you might be able to identify extra synonyms to use to enhance your content. You might be clued in in if certain answers are too vague, if you need to restructure topics so that, they're better paired with the necessary context, and so on. Very good. So the the next question you're all maybe asking, well, is this you know, how easy is this to get started or, you know, is that a heavy lift? So regarding Twilio and the and the ability to migrate to a structured and authoring, I'll pass that to Josh. Right. Yeah. So, you wanna get started with structured authoring if you aren't doing that already. And so, your content, if it's inside Microsoft Word, if it's in Google Docs, if it's in a, you know, a text file somewhere, that might not be as structured as it needs to be. And so if you're planning on moving to a CCMS such as Pligo, certainly, we help lots of people, migrate their content and add that necessary structure. But, you know, once you have it in a a good, structured format, it's not too hard to set up the integration between both Pligo and Zoom in. And then before you know it, the content that lives in your CCMS can be published out on a content delivery platform, and engaged with with, really cool AI applications. Yep. Yeah. So it's really super easy. As we showed you, you'll be able to go kinda get your content, you know, into an AI application. I have to say also because kinda like anecdotal case studies. Some organizations are, you know, nimble and quick and some organizations are a little bit less so. But as a technical talk documentation or a technical content organization, for you to be able to go and say to your leadership, well, you know, we were able to roll out an AI application, a self-service bot like this, with minimal effort. It goes a long way, not just to your your customers and your and your, your partners and your internal employees, but to the frankly, the prestige of your organization and the content that you're creating, it's a it's a it's a big lift. Well, I'd like to also point out that the integration with PolyGo is also is really super simple. It's really out of the box and you just have to start pushing buttons and, you know, the content comes in. But similarly to getting, knowledge based content from CRM systems like, like Salesforce, ServiceNow, Zendesk, it's also super simple. It's basically clicking through a couple of, of a witch of, wizards, and then it'll operate up in this content just flowing in there. And then, and then you're at the start. As you, again, as you as you roll these things out, then you get you get smarter about things. You're able to tweak them, optimizing things, adding and changing metadata. And really getting up and running on something on something pretty powerful is really actually surprisingly surprisingly surprisingly simple these days. So thanks very much for, for participating. We're gonna move over to the questions. I see there are some questions. Yes. Thank you, guys. So what I'm gonna do is I will add a question to the stage. It'll pop up for you. We'll get through as many as we can. We have a lot. But anything we don't get to, we'll get responses together and send them out to everyone afterwards. So, I'm gonna start with Lisa. Okay. We're already using React via Capa AI and Poligo. I'll let you guys address it. However, it cannot see the metadata we add with Poligo. So what metadata are other a AI tools able to see and use? I suppose it's how you, how you design it. Any metadata could potentially be seen and used. What do you think, Joe? Yep. So in in our, integration with Allego, we're definitely pulling out the metadata. So really, it depends on how you're, you know, how you're pulling that content out of Allego. If you're using a tool that's, like, an out of the box tool like like we are that we're providing, we are definitely able to to get the metadata. So I'm sure if we're doing other comp you're also we should be able to do it. But, definitely, the ability to, take out the metadata is is important and, should be able to do that as as well with Allego. K. Can we move on to the next question? We'll move on to the next question. And we have Mark. Mark. So he says, how do you help organizations move content from a tribal knowledge base to a more formal doc set that follows AI ready structured content. Alright. So, I mean, it's a it's a big journey. Right? It's a a matter of strategy, figuring out what your goals are for your content, auditing the content that you already have, deciding, is it in the structure that it needs to be? And if not, how are we gonna get there? And and, of course, you don't necessarily need to move all your content at once. You might start with a subset of a a certain project or a certain department or silo of some kind and, just identify where the logical topics are, where the logical section breaks are, start getting that content into a structured XML type of, format, and then, and and then you're you're there. But it it does take a while. It's not a a small task, but that's what content strategies are for. What do you think, Joe? Yeah. Definitely. I think there's definitely a migration path. I think, you know, folks, I were, you know, in in Beligo, definitely, we've gone through a lot of these type of migrations. So I'm sure you have a, you know, a lot of a lot of fast practice to talk about that. I think what's important also to say is that it is important or useful to get some of that tribal knowledge or a lot of it into a formal a more formal doc set. And so having processes of how allowing your developers and product managers and other people, engineers to be able to create content and submit that content for for editorial or for submission into that larger doc set. Definitely something people can help you with. But, also, I think it's important to understand that not all the content is gonna get in. To me, it does sound content just it's okay that it's it stays tribal, for whatever reason. So you have to kinda play that decide when when the content really needs to be or should be brought in and formalized and have some kind of a curated workflow. And when we you know, when when it's okay to go ahead and point a a connector to it and bring that into our into our knowledge base or into our knowledge to our such as the CDP that we talked about. So it kind of, like, unified knowledge models opposed to how do we when is it the proper time that when is appropriate to basically bring that content and and, and have that curated. I think some of it also depends on, frankly, the resources you have in your team and your prior decisions. So, it's also plays into it as well. Yes. The next question and the one after it are when you're in the demonstration. Does the AI rewrite Josh's text in its answer? I so I, in my experiments, have noticed that it will it'll take phrases from the thing that was in the content and put it in the answer, but it it often kind of paraphrases it to some extent. It it's usually pretty close to what was in the text. And I think there's I mean, behind the scenes, you can tune LLMs with temperature parameters and such if you really wanted to, give answers that deviate a bit from what the source was. But I think for this kind of use case, it's good that it it draws accurately from the content and it doesn't change things up too much. And then on a follow on from that Can you give an example of the I don't know answer? Yeah. So I I imagine we could go to Zoom in and ask it a question about, content that's not in there at all. And, because of the way it's set up, it it it knows not to just say any kind of answer. It's not going to hallucinate as as the phrase goes. I don't know. We could demonstrate that perhaps. But, yeah, the it it's just you ask it about anything that's not represented in the content there, and it will say, I'm sorry. I don't have any information about that. Right. Exactly. Yeah. Well, it'll say in the context of this content, I would I don't have an answer. The the I don't know answer can be kind of configured as well. Mhmm. But yeah. Alright. Now next, we have from Mark again. Alright. Can you train the AI results to understand relevancy of information when presenting it to the user? So I think yeah. There there's the settings I remember in Zoom, and I've seen that knob for, like, personalizing your answers and, filtering based on which publication you want or which tags you want, that can understand the relevancy of the information. Plus, I guess, who you are as a user logged in to the system, might have different roles or permissions, and so the AI can notice who you, the reader, are and give you the appropriate response. Right. Yeah. Yeah. Yeah. I agree with that, everything you said, Josh. The more often in in a CDP, like, it could be, like, in free demo examples I was telling you before, we kind of kind of, went right to a question. But very often, if you navigate and say, well, I'm I'm looking if I land on a page that's for a certain product and then I go ask a question, we can basically configure this the the UI, the the the interface to kind of, filter down the the context of the question based on the landing the product line, the pages that I'm sitting on, for example. That's one way of of kind of creating relevancy. Another way is using that filtering mechanism. Again, another way is that event of personalization we talked about before. What we didn't show again also today is is, is the ability to actually show this little this little, like, CDP or or, like, portal almost inside your product. So one thing to Zoom and also we provide is almost like a little mini portal. We call it in product help or in product assistant inside your application, which also has GPT. And what in that application, the application is automatically only providing answers based on content that's relevant to that particular product. So I might have a a dozen products, but this widget is sitting in inside this particular product, like, in product assistant. I'm only gonna be showing content based on how much relevant. The second answer I wanna show was a little bit more broad is that is that, these, you know, these AI, bots are sometimes driven by semantic search as well. So the semantic search is is more, able to understand context and semantics around the the question. Right? So understanding the relevancy of the of the information based on the the type how the question is phrased can also maybe help to to make a more relevant or more accurate answer. Okay. We have ten more questions, but I'm gonna maybe let's do two more and see how we are, and then we may have to just address the questions and follow ups afterwards. Okay? Sure. Next from David. Alright. So David asks, how do you curate unstructured content for AI, knowledge base notes from customer facing support groups, for example? Or, alternatively, how do you use this for AI if you cannot curate it? Well, so, I mean, you can start small. You can start where content is, not optimally structured, I suppose, where things haven't been fully broken down into subsections or given all the metadata and such. And so you can get some AI answers based on that. But, as we've noted, it it's best once it's better structured, so that it finds the proper context so that it's not wasting money on, tokens for a context that's too large in the prompt. So how do we curate the unstructured content? I suppose you would look at what is most important, what is going to have the biggest impact, and start from there. What do you think, Joe? Yeah. So I think that, in the reality of a lot of situations and companies, we're not able to we still have the resources to curate everything. So often what we'll do in our in what we're we've been doing for a lot of our company customers have been we've been hooking up to their Salesforce KB article, ServiceNow KB articles, or wherever they're saving wherever they're creating these articles, stock over stock overflow, whatever it is. We're able to index them and and provide them as grounded material for the AI, and has has good results. Now but, you know, but, obviously, you know, it would having that content curated or have it being improved will be, be useful. So going back to analytics, seeing which content is actually being used most often to create answers will allow you to go back and decide which content you wanna focus on focus your very limited resources on actually curating or maybe editing. So you might say, listen. This content is getting a lot of a lot of hits or people are asking questions often about this particular, subject matter. And there's a set of articles that we as a content organization don't have control of. Maybe we we do want to either bring that into structure. We wanna make have a little bit more control about how that content is being curated. So I think the analytics around how the how the questions people ask me, how DPT is being in the search is being utilized will help you to focus on which KB articles or notes you actually wanna focus your time on. Yeah. That's a very good point. Okay. Will we do one more and maybe wrap up or if you guys wanna continue? Let's see what the next one is. That's We'll go from there. Is the end user able to select the metadata, or is that something done by the manager of Poligo? Well, I think when you're in Poligo and you're authoring, as an author, you're you're including metadata all the time. So, if the question is, are we able to, select some meta metadata but not other metadata, we can do things like, profile content or filter content so that only some of it is, making it into the content delivery platform given our use case. What do you think about this one, Joe? Yeah. I think it's more of a I think they're more of a little expert. That's why I don't have much to say more more to say about this. But I think you're right. That typically we've done more by the manager, not necessarily the the end user in this case. But no. One of the things that we, I think the what we showed here with the preferences or the user personalization, I think that's probably would be a good example where the end user is actually selecting metadata, and and is actually as part of their interface. So that could be an example of where the the end user is actively using metadata to to affect the affect the answers that they're getting or the the subset of content they're getting. Yeah. Like, by selecting filters and, publications to limit the search to and such. Yeah. Sure. I think we can take another question, Andy. That would be I'm gonna have to read it out because the onstage function has stalled. From Frederick Forsberg, what if we use multiple languages? And his context is we use English plus twenty European languages. Can users ask questions in their own language? Mhmm. Do we have to prepare more than the usual? Well, I know from the Pligo side, translation is something that we definitely have features around. You can create content in multiple languages. You can have even images with language variance and such and publish all of these things over to Zoom in. And, yeah, from what I've experienced with these, AI applications, they do tend to be pretty good about changing between languages or you ask it in your language and it will respond in in your language. And, and if you have the source content in that language, all the better. Right? So what do you think about that one, Joe? Yeah. Absolutely. Yeah. So definitely from a stand from the standpoint of the content delivery, we're also able to support all these different languages as well. We have customers, definitely twenty or more languages. And so definitely being able to import that content, how being have that kind of index, have it the semantic, search around that we're able to support. And, we're rolling out, we're all rolling out over time and build additional ability to have the chatbot actually, work in different languages as well. So that's, something we're have in place, and then we're kind of continuing continuing to roll out additional, like, line, localization or or or localized, content facilities for GPT. But, yes, great question. Cool. Oh, functioning again. I mean, like I said, there's there's six left, and and it's up to you guys, how far you wanna go. Yeah. I I can take this. So how important are taxonomy tags and Poligo for good AI responses? I think they are important. I mean, the more, the better. Well, you know, maybe you don't wanna overload your content with tags necessarily. But if you are thoughtful about it, you look at things like, what audience is this for, what product is this for, what version is this content for, when was it written? Who wrote it? That kind of information that might be relevant to a user deciding what information they're gonna look at, it it's all helpful. So, taxonomy tags, certainly, it it's a a beneficial thing. Right. Yeah. Absolutely. I would agree with that. And and, essentially, kind of to find the point that especially if you're adding metadata, around which adds adds information to what to have content that's basically not written in your text. So for example, if I add metadata like a model number or product name or something that's not actually in the body of the text. So when we're when we're grounding the AI, we're able to kinda take the metadata and add that to the text and the grounding as metadata, but also in the text as well. So the search is able to say, oh, well, someone did a search for a certain model number or they had a question around a certain model number or product or whatever have you. We're able to go and pull out the results and, you know, again, provide the answer even if that model number or that metadata was matching would not actually mention in the text. That's also another kind of technical reason or why why metadata is also important, becomes more and more important as well. Absolutely. That's a great point. Yeah. Great. So Oh, did I move too soon? We're all good. We have issues with our bot reading tables. Is there a Polygo publication template that will publish this in a format for ingestion without affecting the format I want to, anyone using our original help? Well, I think, tables are in Polygo, they're in a structured XML format, which an LLM ought to be able to understand. So, yeah, I guess I'm curious to how your tables are structured currently and, what kinds of issues it's having reading them. But I feel like, you know, tables are the kinds of structure that we've been talking about that add context and meaning. So, yeah. Maybe if we could take a look at your particular use case, we could, see what's up with that. Right. I think that's another example of tables is how multimodal understanding the content is also helpful. Like, we talked about being able to being able to understand that when images what's what's going on inside of an image is part of the AI. Also, understanding a table. Often tape often the AI has a hard time understanding a layout of a table and understanding how things are related to each other. We're using more advanced functionality that frankly we're rolling out and where they have in place. We're able to actually go and understand what the meanings of the tables or what the layout of the table and how that, how that can be more useful as opposed to a bunch of text which is kind of, quote unquote, like, randomly spread around the page, but kind of create meaning around that that tabular information. That's another example of multimodal understanding. Mhmm. Alright. We have three more. You feeling good? Yeah. We have three more. Maybe we'll take one more because, it's in the in the webinar time. Okay. Alright. Can you migrate content from Freshdesk articles to a structured content format? Yes. Yes. I think so. Okay. Almost there. Does Pligo plan to expand its integrations to other AI tools? Well, I don't wanna be specific, but definitely, Pligo is always looking at how we can expand our AI capabilities. Yes. Stay tuned. And the final, more of a statement to address, and we're we're good. Great. Alright. Steven says, I'd be interested in using AI as a tool for implementing an organization's style guidelines and content. Yeah. Certainly, we can, have an AI learn style guidelines. Another thing I know of, Acrolinx is good for, keeping you aligned with style. So if you haven't heard of Acrolinx, you might wanna look into that as well, Steven. Alright. Then, Joe, did you have any final, input there? Yeah. Just real on the last comment, one of the things we we didn't show in the in the example, but, inside the the CTP, we also have an example we call Copilot, which if you click on that, it will if I'm logged in as a as an author or someone internal to your organization, you'll get a little button called Copilot, and it will actually give you a it will give you a, series of of recommendations about how to improve the content, the topic. And you can also would be able to hook that up to a to a style guide, but that might be also useful. I also agree with with, what Josh said. Acrolinx is a company that does this for a living, and we definitely have a good solution there. And then we also have a GPT related, Copilot built into CDP if we're, we're kind of a case by case, topic by topic basis. Excellent. So that, concludes today's conversation. Thank you everyone for joining. Thank you, Joe and Josh, for providing so much useful information to to the crowd. If you'd like to book a demo of Paligo or Zoom in, you have the QR codes there. This presentation will be sent to all registrants in the next, twenty four to forty eight hours, including the deck. And, of course, you are free to contact either of us, at contact at paligo dot net if you have additional questions that you'd like addressed one to one. Thank you, Josh. Thank you, Josh. Thank you, everybody. Have a lovely rest of your Wednesday. Thanks. Thanks, Anne. Thank you. Thanks, Josh. Bye.
Aug 15, 2024